
 FreeBMD : Transcribers' Knowledge Base
FreeBMD : Transcribers' Knowledge Base
FreeBMD : Transcribers' Knowledge Base
FreeBMD : Transcribers' Knowledge BaseWe have a range of transcribing aids which can be found at: http://www.freebmd.org.uk/addons/
This is not normal. You should ensure that you start the program BMD.EXE instead of BMDPACK.EXE
Start with the cursor in the BOTTOM cell of the column with the missing entry. [Alt+D] will move the lowest entry to the blank cell below, empty the cursor cell and then move the cursor up a row. Just keep hitting [Alt+D] until you get to the line where you want to type in the missed value.
Please note that Block input is deprecated as it can give rise to large numbers of errors.
Try Block Inputting. When you have started the batch, press F5, and you can enter data in columns. Enter the surnames then forenames ([Alt+V] automatically copies the name entry until you let go of the buttons), then the district, and finally, the page number. Have a look at SpeedBMD "Help" F1 to invoke the associated help. Read Section 17 on Block Inputting to get to grips with all the features.
Please note that Block input is deprecated as it can give rise to large numbers of errors.
Press Alt+Enter - this will toggle between Windowed and
Full screen mode.
OR:
(Start here if you are starting the program from the
start menu:-) Left Click on the Windows "Start" button, select
Settings...Taskbar & Start menu, select Start Menu Programs...Advanced,
open the Programs folder, find the shortcut,
(Start here if you are
using a desktop shortcut:-) Right click on the shortcut, select
Properties, select Screen, in the usage box, select "window" Click
OK, (End here if you are using a desktop shortcut) Close the Explorer
window.
Have a look in the small window at the top left hand corner of the SpeedBMD screen -- it should say Auto. If yours says 4 X 6 or anything else, then open the list by clicking on the small black diamond at the right of the window. Scroll up to the top choice (Auto). Now click in the centre choice of the three at the top right hand of the screen (the thing that looks like two overlapping squares). You'll need to do it twice to get back to your old familiar screen.
Note: The above might not apply if you are running Windows XP or 2000. You are advised if running one of these operating systems to use WinBMD which can be downloaded here
Press F1 for the SpeedBMD Help file on any topic.
For SpeedBMD 1.7, Using notepad, open the file bmdscr.txt At the top of the file, alter the lines c:\windows\winhelp and c:\windows\notepad to c:\winnt\winhelp and c:\winnt\notepad. Save the file, and it will work OK
I've come to the conclusion it is an insufficient memory problem when your Supplementary District
table gets to about 150 entries or 2.5K.
If you hit this problem please let me know [email protected]
and send me a copy of your c:\speedbmd\bmdsupp.txt file. If you then delete this file your system will
work OK again.
Open the batch in notepad (it is a text file), and print it out
FreeBMD has little interest in the batch numbers allocated by SpeedBMD, so long as they are all different for the same transcriber. It will be no problem therefore if you just retype the lost batches and let SpeedBMD allocate the numbers automatically. Your old .001 then becomes .005 and your old .003 becomes .006. For the benefit of posterity you could put a comment line at the start of the batch saying something like - *This was originally batch .001 which was lost in a disk failure. The problem does beg another question. Had you uploaded any of the batches to FreeBMD before the disk failure? If you did then we have another story altogether.
SpeedBMD supports the arabic pre-1852 format!
When starting the batch, select format "99" instead of "XX" and you get the arabic version of the old
style volume numbers.
Under version 1.9 (or later) of SpeedBMD then press Cntrl/F7, under earlier versions press the "~" key and select from the list of characters.
It is the facility within SpeedBMD that, as you type in a district name or a forename, provides a list of potential names that match, to cut down on typing.
This problem seems to occur if SpeedBMD has crashed for some reason or if shut down by doing a Windows
"Close" instead of using the [Esc] key.
In these situations it seems that Windows does not release all the files acquired by SpeedBMD so next
time you start SpeedBMD it thinks a file is already in use elsewhere.
The only known solution is to shut your PC down and start it up again
You need to copy the file(s) you were transcribing to the folder where you installed SpeedBMD on your new machine. If you are part-way through a batch or file you will also need to copy over the BMDPROJ file (see below).
Then, when you start SpeedBMD, using the Enter key will allow you to continue to edit the partly-transcribed file, and using F4 allows you to edit your transcribed file.
If you have the original SpeedBMD files you are recommended to copy these files to the new SpeedBMD folder:
| BMDDSUP.TXT | This gives you the supplementary district codes that you have added. | |
| BMDNAME2.TXT | This is your amended forename pick file containing the names you added using F7. | |
| BMDPROJ | This is the file that records header details of the last file you were transcribing. If you copy this to the SpeedBMD folder your latest transcribed file will be shown as the "current batch" when you start BMD. |
Note that this works if you move between any older version of Windows and a newer version (e.g. from Windows 95 to Windows 2000 / Windows ME)
For versions of WinBMD prior to version 7, install WinHlp32.exe from the Microsoft Download Center.
Alternatively, open Windows Explorer and go to where you installed WinBMD (probably C:\Program Files\WinBMD). Click on "Compatibility Files" button in the heading and then the folder Output will appear (this button only appears when there are files hidden). Your transcription files will be in that folder. However, this will not work if you access this folder from another application (e.g. a browser or BMDVerify), in this case you will need to navigate (by clicking on each item) to Computer\c:\Users\username\AppData\Local\VirtualStore\Program Files\WinBMD\Output where username is your user name which may be "You". If you don't see one of these folders (e.g. AppData) you need to get Windows to show hidden files - click on Organize and then Folder and Search Options and in the View tab select "Show hidden files, folders and drives" (you may have to scroll down to find this). Once you have done this once your application should remember the location next time you want to access files.
This latter method also works if you need to access other folders under WinBMD, such as the Files folder, instead of the Output folder.
To correct this select the Options menu and uncheck "SpeedBMD filenames".
Only characters that are part of the character set ISO8859-1 are valid. Using characters from the Windows Character Map won't work.
Row N: Row is incompletewhich are rows for which you have not entered anything in the Age at Death field. If a field is empty you should transcribe ? for the field. Enter ? for Age at Death in each of the rows given in the message.
It has been found that sometimes WinBMD appears to get confused about the version of the district file you have in use and so will not download a newer version because it thinks you already have it when you don't. You can check this out as follows:
WinBMD_Districts.txt. Now click on Get data file version. This should
give you the version or say that the version is not recognised.
\Program Files\WinBMD\WinBMD.ini
To use File Management click here. You will need to log in using the same user id and password that you enter in the header screen of WinBMD. You will be presented with a list of your files; find the file concerned (if it is a file you have just uploaded, selecting 'Date Modified' and 'Descending' and then clicking on 'Display/Sort file' should show the file you require as the first file).
Where the index page number has a suffix (e.g. +PAGE,234a) and WinBMD cannot handle such page numbers transcribe without the suffix and then change the file using File Management.
If the page you are transcribing has a page number suffix you will need to change both the filename and the first +PAGE. Using the page number without the suffix is a problem if you have already transcribed that page. For example, you have transcribed page 235 and now need to transcribe page 235a; you cannot transcribe the file as page 235 because you already have a transcription with that page number. To get round this add a numeric suffix, for example 2351.
If it is the next page that has a page number suffix you will need to edit the last +PAGE in the file.
To enter such a volume number:
When you want to upload the file select Options/Do Not Validate Districts and then do the upload.
The page numbers are hidden off the right side of the window. To correct this put your mouse over the right edge of the window and it will turn into a double headed arrow. Holding down the left mouse button move the mouse to the right to increase the size of the window until the page numbers appear.
If you want to adjust the width of any of the columns, you can use the same method on the column headings. Put your mouse over the line between the column headings and it will change into a double headed arrow. Holding down the left mouse button and moving the mouse allows you to adjust the column widths. You can also do this with the line to the right of the Page heading to adjust the width of the Page column (make the window wider if you cannot see the right hand edge of the Page column).
Some header details you can change using SpeedBMD, use the following method for all but the
Fiche/Film/Page number and the Event Type (B, M, D)
In SpeedBMD, at the front screen press F4 (Correct an earlier batch), highlight
the batch you want to change, press "Enter" key, then under "Options before
starting surname", press F4 (Review Heading) again and just "tab" to the relevant item you
want to change.
To change these other two fields you will have to get out of SpeedBMD and use the Notepad program to
open the file you are working on. It will display the DOS text in the file and you will see
MARRIAGE, BIRTH or DEATH in the top line. The word can be changed to whatever it should be and the
file then saved as a different name. If you look at the file name, the second letter denotes what
kind of record it contains:
M for marriage
B for Birth and
D for death
Change the file name carefully and then save it. As a precaution, make copies of before and after.
You also need to edit the file name within the file (on the second line) otherwise SpeedBMD gets
confused.
Make sure you are working on the right file next time.
The notepad approach is good for fixing any other little errors in the header discovered after you have
started.
You will have to go into Notepad to do this.
Once there do the following:
Substitute your own values for the items in red.
[File] [Open]
Files of Type [All Files]
Find the file for your batch 68M10132.SCA and click on it.
The data displayed should look something like that below
+INFO,aa@,password,SEQUENCED,BIRTHS,cp437
#,9z,Peter,test, 68M10132 .SCA,03-Oct-2000
#,
+S,1899,Jun,,03-Oct-2000
+PAGE,132
Change the file name embedded in the second line to 69M10132 .SCA
then
[File] [Save as] 69M10132.SCA
[File] [Exit]
Now go into SpeedBMD
Hit [F4], you should see the names of your error batch and the corrected version in a list to the right.
Hit [up/down] to get to your error batch 68M10132 .SCA
Hit [Delete] twice
Hit [up/down] to get to your corrected batch 69M10132 .SCA
Hit [Enter] and the corrected batch is now your active batch and you are on your way again.
The source reference should indicate whether they are scans of GRO fiche or LDS film. The reason for
the distinction is that Fiche/Film/Scans are all copies, and may lack the clarity of the original, or
even miss pages from the original. It will be helpful when cleaning the data to know which source each
transcription derived from.
There is no need to print them out. You will find it easier to view the image on the screen using an image viewer, along with the transcription software. (SpeedBMD or WinBMD)
If you check in the message that came with your first allocation, there is a URL for a freeware TIFF viewer!
Your syndicate co-ordinator should have given you instructions for obtaining your next allocation. Please contact him/her for details.
Yes. In scan batches, the last 4 digits are the page number you are transcribing.
Right click on the file and from the menu select Save Target As...Select the folder where you want to store the file, and download into that folder.
 icon next to the entry to be corrected).
icon next to the entry to be corrected).
In particular, if a name is all in upper case transcribe it as such, so ROBERTS,HENRY should be transcribed as "ROBERTS,HENRY". However, if the entry is in an upper case font like this ROBERTS,HENRY transcribe it as "Roberts,Henry", since we are not transcribing the shape of the font but the meaning of the font.
If the original field is crossed out, transcribe the entry with the amendment and add a comment:
#COMMENT handwritten amendment of crossed out <fieldname> <fieldvalue>where <fieldname> is the name of the field (surname, page number, etc.) and <fieldvalue> is the original field value. So, for example, a change to a page number might be
#COMMENT handwritten amendment of crossed out page number 541
If there are multiple fields involved repeat <fieldname> <fieldvalue> for
each field, e.g.
#COMMENT handwritten amendment of crossed out volume 3b page number 541
If the original field is not crossed out, transcribe the line twice, once with the original field value and once with the added amendment. After the first entry add a comment:
#COMMENT(2) original <fieldname> of <orginalvalue> had a handwritten added amendment of <newvalue>where <fieldname> is the name of the field (surname, page number, etc.), <originalvalue> is the original value of the field and <newvalue> is the original value plus the added amendment. (This form of comment causes the comment to be attached to both entries.) An example of a single amended field might be:
Davies,Sian Louise,Davies,Pontypridd,27,1276 #COMMENT(2) original page number of 1276 had a handwritten added amendment of /C4239 Davies,Sian Louise,Davies,Pontypridd,27,1276/C4239where /C4239 is the added amendment.
Repeat the above comment text in the same #COMMENT(2) line if multiple fields are involved.
Also see question 6g
Type "de" which appears as "De". Hit [Home], to get to
the start of the field, then type "d" again, which now stays as
"d". Hit [End] and carry on with the rest of the name.
Well, ideally, if they are written that way they should be transcribed in upper case, but I suspect we will be lenient on case changes for matching purposes. It would be good if a comment was added to the files to the effect that this error has been made. All future entries should be in the SAME case as they are in the source you are transcribing.
If the appropriate point for insertion is shown by "x" dagger
asterisk etc. then transcribe the extra record as if it was actually at that
point (option a).
If no insertion point is shown, then insert at the bottom of the page or column
as shown on the manuscript.
"&c" is an abbreviation for "et cetera". You should enter it.
See question 6b
Yes. It is almost certainly the same person, and means that the original entry is indistinct.
There is a way of telling which is which on the typeset pages even if the character is faint.
The vertical stroke of a "1" is aligned with the centre of the characters above and below, the vertical
stroke of a "4" is aligned with the right hand edge of the characters above and below.
Having an r in this position is not a normal typographical convention - e.g. if it had
been an F followed by a raised r on their own one would have recognised it as an
abbreviation for Father. Therefore we have to decide which other letters it is related
to. It is either a dropped r from E nest or it is an insertion into Fanny. Having
decided which is the most likely that is what is transcribed, i.e.
Ernest and Fanny, optionally with a #COMMENT
or
E nest and Franny, with two #THEORY lines
The first of these is the much more likely to be the best choice in this situation.
The situation with large and small letters in a capital font is interesting. Although the font is in capitals (that is the shape of the letters) plainly the first letter is larger. Since we do not transcribe the shape of the font but the meaning, the closest to this font is to transcribe the first letter as upper case and the rest as lower case since this differentiates the first letter from the rest and hence retains the meaning of the original.
To demonstrate this typing the letters "Smith" into what is known typographically as a Small Caps font might give this 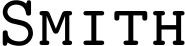 and, indeed, it is highly likely that this is how the index was created with this type of font.
and, indeed, it is highly likely that this is how the index was created with this type of font.
Transcribe it as 8[ce] - this indicates that the uncertain character is either 'c' or 'e'.
It is recommended volunteers start a new batch to correspond with each page of the index. For example, this would mean approximately 375 entries per batch for typed Index pages which have a nominal maximum of 375 records per page.
Should there be a need to include more than one Index page per batch it is an important requirement to include +PAGEs to correspond with each Index page.
The transcription software is unable to handle superscripts, so just transcribe it as McDonald. This applies to all words with superscripts.
Type the split line as one and omit the hyphen and the curly brackets, thus:
MONTROSE,Douglas Beresford M.R. (Duke of),St.Geo.H.Sq.,1a,1140
These "see later date" entries are important; they are for people
who were registered late. The surname, forenames, districts and volume numbers usually follow the set
pattern but the page number contains a reference to a different date and/or page number e.g. "see Jun/35",
"D/1035", "see /22", etc. These references should be entered as seen in the page number field, so
Tarrant,Leslie,I Of Wight,2b,Dec/1926 in the example given. In some cases the volume
number is missing and should therefore be entered as ?, so
Pullen Mabel Axbridge see S78
should be entered as Pullen,Mabel,Axbridge,?,see S78.
If the details in the page field indicating a late entry do not conform to a format recognised by
FreeBMD a warning message will be shown against the file. An example of a recognised late entry
reference is see M/88. If, however, it was see Septbr/95 then it would
not be recognised.
If you get such a warning add a line after the entry with the following format:
#THEORY,REF,see S/95where the quarter must be M, J, S or D and the year must be either two or four digits.
Multiple lines can be covered with the format #THEORY(N),REF where N is the number
of lines covered (including the preceding one).
It is not necessary to include #THEORY,REF if there is no warning against the entry.
For line 30, you MUST enclose the whole of the district field in quotes, to ensure that the software knows that the comma is a part of the district, rather than the comma that separates district from volume. So, for example, your entry should be Drew,Albert,"Bradford, Yk.",9b,69
The bad format error on line 54 is caused by the semi-colon before the 11a which should be a comma. There is a difference between what you type in the District field in speedBMD and the actual text file you upload to FreeBMD. In SpeedBMD you enter a District with a semi-colon but it is then converted by the program into a comma. If you are not using SpeedBMD then it must be entered as a comma.
Transcribe the line twice:
Hickford,Mary Ann,Kingston,4,251 Hickford,Mary Ann,Kingston,4,250A
In nearly three years of transcribing for FreeBMD I have seen many examples of daft folks giving forenames such as Bishop, Lord, Earl, Doctor, Squire, Colonel etc. to their *new-born* children. I doubt they came with these ranks and degrees built in. :-)
#COMMENT Surname has alternative name CHAPMAN
If it is not the surname or you cannot determine if there is an entry for the second name, transcribe both names using 2 lines (repeating all the other information such as forename, district, etc.) and add a comment after the first line specifying how the original entry reads. For example
BONUS or CHAPMAN,John,Marylebone,1a,521should be transcribed as
BONUS,John,Marylebone,1a,521 #COMMENT(2) entry reads BONUS or CHAPMAN for surname CHAPMAN,John,Marylebone,1a,521or, in Births,
Bridgestone,John,Bonus or Chapman,Marylebone,1a,521should be transcribed as
Bridgestone,John,Bonus,Marylebone,1a,521 #COMMENT(2) entry reads Bonus or Chapman for mother's name Bridgestone,John,Chapman,Marylebone,1a,521
So, in general, the comment should read:
#COMMENT(2) entry reads <original> for <field>where <original> is the original wording from the field of the record and <field> is the field in the record which is
surname,
given name, mother's name,
spouse name, district,
volume or page number.
Note that there is no space between "#COMMENT" and the "(2)".
If there are more than two names, enter one record for each and put in one
comment covering all the names, e.g. #COMMENT(3) after the
first of three entries.
If there are aliases for more than one field, transcribe each possible combination and put in a #COMMENT to cover them all which gives each of the aliases found, e.g.
Bridgestone,John,Bonus,Marylebone,1a,521 #COMMENT(4) entry reads Bonus or Chapman for mother's name, 521 or See D/93 for page Bridgestone,John,Chapman,Marylebone,1a,521 Bridgestone,John,Bonus,Marylebone,1a,See D/93 Bridgestone,John,Chapman,Marylebone,1a,See D/93
There is no need to insert a #COMMENT.
If no insertion point is shown, you transcribe the record in the location shown in the index even though it will flag up as an out of sequence entry - see here.
See also question 6an
No, just transcribe without a break.
Include the entry and then in the line underneath put:
#COMMENT Entry crossed through
This also applies to a handwritten addition which has been crossed out and replaced by what is essentially a similar handwritten addition.
It is not necessary to transcribe such pages. However, if a blank page is one of a double page scan you can include consecutive +PAGE lines, e.g. if page 123 was blank you could include
+PAGE,123 +PAGE,124
You have probably clicked on the Option menu in the Toolbar of your transcribing page and accidentally chosen SpeedBMD Filenames, as indicated by the tick beside "SpeedBMD filenames". To return to ".BMD" suffix filenames you need to click on "SpeedBMD Filenames" in the Options menu to remove the tick.
Transcribe the entry as written. You may get a warning but, having checked that you have correctly transcribed the entry, you can ignore the warning.
Where a scan contains two pages of the index enter a +PAGE with the number of scan at the start of the
file and a +PAGE with one added to that number where the second page starts in the transcription. So
for a scan file 1843M1-C-0125.jpg the transcription would be:
+PAGE,125 .... +PAGE,126 ....
The same applies if the scan number has a suffix, so 1843M1-E-0081-a.jpg would be transcribed as
+PAGE,81a .... +PAGE,82a ....
Transcribe without the question mark and add a #COMMENT line after the entry stating what the field contained. If we allowed the entry to contain a question mark it would not be found in a search so we put in a comment to indicate the entry could not be transcribed exactly as in the index.
#COMMENT indicates that what has been transcribed is not what is in the index but is an attempt to get as close as possible. The difference is described.
#THEORY indicates that what has been transcribed is what is in the index but there is reason to believe the index is wrong. It describes what it is believed should be in the index.
This is a handwritten entry and the letter you are interpreting as an "f" is in fact the way an "s" was written when preceding another "s". In typescript we have only one "s" and so both written forms are transcribed as "s". Please see here for some examples.
FreeBMD will not allow an entry which contains a numeral in a name/surname field to be uploaded and WinBMD will not allow a numeral to be entered in a name/surname field.
To overcome both these limitations transcribe the entry and substitute any digit by an underscore character (_), then add a #COMMENT to show that the entry could not be transcribed as shown in the index, e.g.
SILLITOE,Mary Sten_ng,Wirral,8a,374 #COMMENT Index entry for Sten_ng contains numeral 8 which has been been substituted by _and upload the transcribed file to FreeBMD.
 giving details of the scan.
giving details of the scan.
The names should be transcribed on the the page which they actually appear and should not be moved from one page to another. The comment may be like "see ..." which indicates where out of order entries are to be found. Where this includes actual names these should be considered part of the comment and should not be transcribed.
However, use the +BREAK line in your transcription to indicate the discontinuity, as follows:
1) +BREAK before and after the block of names on the incorrect page
2) +BREAK at the indicated insertion point on the correct page
A practical example of using +BREAK where the first entry on page 1145 (i.e. Warren,Elizabeth,Luton,3b,430) is indicated by a mark as being more proper to page 1144. Page 1144 also has an insertion mark to indicate where the entry from page 1145 should be entered.
+PAGE,1144 Warr,Sidney,Bath,5c,719a ... [rest of entries down to] Warren,Elizabeth,Birmingham,6d,96 +BREAK ... [rest of entries down to] Warren,Elizabeth Anne,Totnes,5b,167 +PAGE,1145 +BREAK Warren,Elizabeth,Luton,3b,430 +BREAK Warren,Ellen,Newton Abbot,5b,123 ... [remaining entries]
+BREAK marks the insertion point on Page 1144
+BREAK marks the start of the out-of-place entry on Page 1145
+BREAK marks the end of the out-of-place entry
From version 6, WinBMD has an option "Space After Forename Period". Deselect this option to stop WinBMD inserting the space.
For previous versions of WinBMD you need to backspace and remove the spaces.
Isaacs,Jennie,Wiggins,Rochford,4a,1736 & 1804should be transcribed as
Isaacs,Jennie,Wiggins,Rochford,4a,1736 #COMMENT(2) entry reads 1736 & 1804 for Page No. Isaacs,Jennie,Wiggins,Rochford,4a,1804The wording on the #COMMENT(2) line should be amended to accord with the specific circumstances of the entry.
These are standard forms of correction on typed pages and the entries should be reordered as indicated.
It is normal practice for the second of the duplicated scans to be
annotated in the scan name to show it is a duplicate of another scan; transcribe the scan without the annotation. If
there is no annotation to indicate the duplicated scans please contact the
 with details of the relevant scans and transcribe the first scan.
with details of the relevant scans and transcribe the first scan.
Note:
WHITEBROOK
JAYNE MICHELLE POTTS OR STATHAM
BURTON 9B 112
Splitting the entry across two lines is purely a typographical convenience and it should be
transcribed as being a single entry in the index (to which, in this case, the requirements
of 6(u) would then be applied).
It is quite possible that such insertions are not "official" - the books that contained the index were, in the past, available to researchers and it is quite possible a researcher added the insertion. Nevertheless, the insertion may contain correct and valuable information.
Whatever the provenance of the insertion it should be transcribed using a # comment, that is without "COMMENT" or "THEORY" (since these refer to a particular entry), and an email should be sent to giving details of the scan and the insertion. So in the example given above the comment might be
# see HEDGKINSON,Emma
However, there is an exception to this if the surname in question is the last entry on the page and the next page starts with the same surname. In this case do not transcribe the surname since this appears to be a fault in the process that the GRO used to create the index and does not convey any information.
No. It is *far* more important to be precise. It is very easy to make a presumption about what the "correct" district name is, and to be wrong in that assumption. The FreeBMD system standardises all the variant spellings into 700 standard districts. If there is a mistake there, we can correct it, and put right all the entries in 5 minutes. If there is a mistake in several transcribers files, it takes a lot more effort to put it right.
Type Kirkstall;9b and it will accept it. It will also ask if you want to add the district to the pick list. Say yes. You should also do *exactly* the same for any district name that is in the index with a different spelling to the pick list.
The reason that it looks like N Bierley is that it is N Bierley!
You must never try to make a district fit in with the standard names in SpeedBMD.
If it says "Peterboro'" don't pick the Standard "Peterborough" from SpeedBMD, transcribe it as
"Peterboro'"
In this case, North Bierley was only created in 1892, and is missing from the list of standard
districts.
If you type ;6b etc (you need the semicolon for both volume number format) followed by the tab key, alphabetical districts will appear for you to scroll through.
Using Notepad or Wordpad, first select the SpeedBMD Directory. There is a file "bmddsupp" in this folder which holds all of the additional districts which you OK. Make the amendments carefully to correct the spelling, or delete the entry, and then save the file.
You can't, currently.
(ii) You will also need to change the email address on the FreeBMD mailing lists to which you are subscribed by sending an "unsubscribe" request from your old email address as described at: http://www.freebmd.org.uk/lists.shtml followed by a "subscribe" message from the new email address.
Answer. You will receive an e mail as below. It is strongly recommended that you immediately click on
the shortcut link to confirm your registration in the section marked IMPORTANT.
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
Dear FreeBMD Submitter,
As promised, here is an email confirming the details of your registration as a FreeBMD Submitter.
First Name : John
Surname : Thomas
Country : Wales
E-Mail Address: [email protected]
Submitter ID : Johnnyboy
The email address of your Coordinator is [email protected]
IMPORTANT: You MUST return to the FreeBMD site and confirm your Submitter ID before it is enabled for
transcription. The Easiest way to do this is to go to this link:
http://www.FreeBMD.org.uk/cgi/bmd-files.pl?challenge=A1BCDE and login
with your Submitter ID and Password. Your Submitter ID will be automatically confirmed and your
Coordinator will be notified.
If, for any reason, you try to logon to the site without having completed the above process, you will
be prompted to enter a 6 character challenge.
Your 6 character challenge string is: A1BCDE
Should you have any problems logging on, please contact your Syndicate
Coordinator or email the FreeBMD Volunteer Coordinator at
[email protected]
Thank you again for volunteering as a FreeBMD submitter.
Yours,
Camilla von Massenbach
Ben Laurie
Graham Hart
FreeBMD Project leaders
Please make sure you have joined one of the FreeBMD mailing lists.
@@@@@@@@@@@@@@@@@
The reason for a challenge... When you register you put in an email address. We want to validate that you are the owner of that address so we send you a challenge. Before you can use the facilities available to you via the login screens, you need to enter in the challenge we sent you. People are prompted for their challenge when they first log on. Once you have entered a successful challenge you will not have to do it again ...
Go to the login screen and choose the option to reset your password. When you reset the password it is sent to you with a new challenge which you can then use to validate your id. Sorry about the inconvenience, but it is necessary if we are to avoid having a database full of invalid data ...
I've seen this problem a couple of times, always with Netscape browsers. Try clearing the cache, and logging in again.
The curly brackets are not being accepted. Transcribe them as round brackets since the style of brackets is to do with the typology not the meaning.
Do *not* upload an identical page twice, otherwise it will appear as though the file has been double-keyed. Just ignore the second scan.
1) Is the message in the main browser window, or in a popup box? If it is a popup box, then the
most likely explanation is that there is temporary congestion, and the link has timed out. You just
need to try later.
2) If not, are you sure you have the details on the upload screen correct?
Filename: 68M30144
Upload: C:\speedbmd\68m30144.sca
Content: (empty)
The exact value of "upload" will vary depending on where you installed SpeedBMD, but the example
above is the most usual. You can ensure that you get the value for upload right by using the "BROWSE"
button, and selecting the file from a list instead of typing it in.
Transcribed files are only incorporated into the database about once a month - this is known a updating the database and it takes quite a long time. Any files uploaded before the updating starts are included, those uploaded after it has finished are not. You must have uploaded your files during the updating and so some were included and some were not. They will be included in the next update.
Start a new Project for each event in each quarter. Personally, I open a new batch at the beginning of each new fiche frame that I start, (about 370 entries) and upload it to the database at the end of the frame.
There may be a number of reasons for this error.
Or:
These files are your personal record of what you have entered onto the database. The list will remain there in case you need to edit any entries, or replace any files.
Leave it where it is. Warning messages are warnings, rather than errors, because they are to draw attention of a human to a possibly incorrect situation. They leave the human to decide :-)
If it was wrong you would get an error, not a warning. A warning indicates that whilst the data will be accepted there is something about it that warrants further checking. In the example above the system noticed an anomoly and is requesting that the transcriber checks that what they have transcribed is what is in the original.
Bad format at line 4 (+F,1867,Mar,,132,0951374"Office of Population Censuses & Surveys Titchfield Hampshire England General Index Marriages MAR A-Z 1867 Microfilmed by The Genealogical Society Salt Lake City Utah USA 31 July 1974,11-Oct-2000) Expecting a +F, +B, +M, +S or +U line at line 5 (+PAGE,366)What has gone wrong?
The format of the +F line is; +F,Year,Quarter,FicheRange,FicheNumber,Source,TranscriptionDate
The FicheRange is optional.
The problem lies in your "source" field; 0951374"Office of Population Censuses & Surveys Titchfield
Hampshire England General Index Marriages MAR A-Z 1867 Microfilmed by The Genealogical Society Salt
Lake City Utah USA 31 July 1974
The " after the film number is causing a problem. I suggest you change the source reference bit to just
LDS-0951374
In fact, if you are transcribing from film, you should be using a film header instead;
+M,Year,Quarter,FilmRange,FilmNumber,Source,TranscriptionDate
So that would give you:
+M,1867,Mar,,0951374,Brief description of where you got the film from,11-Oct-2000
It is your choice whether you keep files on your PC (although your syndicate may have specific rules). Once a file has been uploaded the file remains on the server and available for incorporation into the database unless you delete it. It is backed up regularly. Deleting the file on your PC will NOT affect the copy we have on the FreeBMD server. If you delete a file on your PC and then need to amend it you can either do the amendment directly in File Management or download the file in File Management, amend it on your PC and upload it again (e.g. using WinBMD). To download a file click on the Download button next to the file - you should use the Download with .bmd extension button on the next screen if you want to edit it with WinBMD.
If your name is still showing zero entries, then your uploaded file hasn't been accepted; here are some
things to consider:
1) The update takes some time and may have started before you did your upload (the cut off date and
time is given on the Latest FreeBMD Database Import page).
2) Did you get any error messages as you uploaded.
3) Did you get a message saying <file> created when you uploaded
4) When you go into file management, can you see the files listed
Legally data is owned by the copyright holder. In the case of the index data being transcribed this is the Office of National Statistics (formerly the General Records Office). The ONS have given permission for FreeBMD to translate the data into a digital form and make it available, free of charge, on the Internet. FreeBMD has given transcribers permission to transcribe the data on behalf of FreeBMD and, in a limited way, to manage the data. However, ultimately, in accordance with the agreement with the ONS, FreeBMD is responsible for the management of the transcribed data.
Having the search deal with different variations has not been implemented yet because we are
concentrating on the transcribing, not the searching at the moment.
In the meantime, using * for missing/duplicate characters in a search will work but continue
using [ ] _ etc when transcribing.
There are very few occasions when you should delete a transcription file (using File
Management). In most cases files should be replaced using File Management facilities, or,
if this is not appropriate, deleted immediately before the replacement is uploaded. Even if you
have transcribed the wrong file by mistake please do not delete it without consulting
 first otherwise it can cause lots of problems.
first otherwise it can cause lots of problems.
Go to File Management and next to the file you want to download click the Download button. Note that the file should only be edited using the software that originally created it otherwise non-English characters may be handled incorrectly. Copying and pasting from Show File or from View in File Management is unsafe because of character set encodings.
These pages should be transcribed with a name that has the numeric value from the scan file name with the suffix S, such as 1985BA0001S.jpg.
In order that the entries from such pages are ordered correctly it is important that the type of the file is RANDOM in the +INFO line.
To create a RANDOM file using WinBMD (or other transcription software), create the file as normal, which will create a SEQUENCED file on your computer. Then separately use a text editor (such as Notepad - do not use a word processor) to make the following amendments to the file on your computer
An alternative way, which avoids using a text editor, is to upload the file created by WinBMD and then go into File Management to make the amendments above. This can also be used to amend files already uploaded.
I get the same quirk with +INFO and the like when I convert to csv. It doesn't appear to matter since as you say it is only a display problem, the database accepts it OK. I've uploaded quite a few files now and it happens. I have tried a number of fiddles to get rid of it but it always seems to come back. Oddly enough when you open the csv file in Word the original typing appears. I find it is necessary to do this to check that one has not over-run and introduced any commas after the last +PAGE line. If there are any the database will not accept the file. For the sake of people not too used to Excel it is necessary to type a ' before inserting the +INFO type of data otherwise Excel thinks it's a formula being entered when it sees a + .
Generally "export to a text file first".
Use the F9 key to show a character map, from which diacritical characters can be selected, to actually transcribe the character. Having completed the transcription open the file in a text editor and add the characters ",unicode" (without the quotes) to the end of the first line. Take care to save as text only, that is without formatting information.
You can now upload the file normally using File Management.
MacBMD needs to be updated so that this field can be entered but in the meantime
there is a workaround available which is to add the registration date to the
end of the District, separated by a comma. An example might be Droxford,09.84.
Because, eventually, all data will be keyed twice (i.e. double keyed) by two independent syndicates using if possibly two different sources of GRO indexes. This is in order to ensure that keying errors by transcribers are minimised.
Peter Cox of SpeedBMD fame has designed 2 posters for FreeBMD at the following addresses. These can
be used wherever you have permission to pin them.
Poster1 and
Poster2
The data in question was used by the project right back at the beginning to test the database,
BUT...
The data isn't actually what Mike found in the index, it is what he found in the index plus Mike's
corrections.
Whilst this might seem like a good idea (surely we want corrected data), it doesn't fit in with the
FreeBMD model, which relies on us having an absolutely literal transcription, together with
separately identified corrections.
Having said that, it might be worth thinking about loading the data into FreeBMD temporarily until
this range is transcribed
The FreeBMD official verification process is described on our Web Page "Transcription and Verification Process" at http://www.freebmd.org.uk/process.html This involves double keying of the index by a second and independent Syndicate using the various tools available on the FreeBMD site.
You can order the appropriate Certificate from the General Register Office(GRO). The process and relevant costs for obtaining a Certificate are shown on the GRO web site.
It may be possible to obtain a reduction in the Certificate fee if you are able to provide the details from the FreeBMD search for your ancestor, such as District, Volume and Page Number (however we make no warranty whatsoever as to the accuracy and completeness of the FreeBMD data).
From 1912 onwards the actual GRO Index also includes the name of the spouse.
You will find the mailing list archives here .
No!
When individuals sign up to commercial organisations (such as findmypast.com, Ancestry etc) offering scan images they must agree to and abide by terms and conditions which most likely prohibit such use of scans downloaded from these organisations.
In consequence, in order to protect both FreeBMD and indivduals from potential legal action, FreeBMD will not accept any transcriptions created from these sources.
FreeBMD take their responsibility seriously and if we believe that transcriptions uploaded to FreeBMD come from commercial organisations offering scan images they will be removed. This way we are able to show that we are taking real steps to prevent illegal use of commercial organisations' scans.
Please see answer to question 13(b)
By way of a practical example:
Consider a page of 40 entries, double keyed, with 3 entries transcribed differently by the two
transcribers.
That gives 80 total records. It also creates 43 distinct records, giving an overcount of 3 records to
the total and messing up the stats.
We now analyse the alignment of unmatched records, and do an additional count on records which don't
actually match, but which (because of their sequence) are obviously different transcriptions of the
same entry, and in the unique records count, only count them once, thus giving 40 unique records.
This achieves two things:
The copyright holders will grant permission.
However, in some circumstances, e.g. when a birth is re-registered, a further supplementary copy is sent by the Registrar to the General Register Office which supersedes the original copy and in these cases the new entry is given a supplementary number.
This means an original page number in an entry such as 495 might be crossed out and replaced by a page number such as 1659/S.
There are a number of reasons for re-registering a birth, such as:
In the early days of FreeBMD some of the scans that had to be transcribed were
very difficult to read which lead to extensive use of UCF (Uncertain Character
Format) symbols to indicate the uncertainty in the transcription. Later much clearer
scans became available and were used for transcribing the same information albeit with
much less uncertainty. There was therefore a need to "retire" the earlier transcriptions
but in order to give credit to the transcribers this was done by marking the early
transcriptions as "superseded". This means that the entries in the early transcriptions
are not included in the search results but the details of each entry (accessed via
the icon) give credit to the early transcribers as well as
the transcribers of the displayed entry.
Transcription files are marked as superseded by the Syndicate Coordinator making a
request to .
Last Updated 15th March 2022
| Search engine, layout and database
Copyright © 1998-2026 Free UK Genealogy CIO, a charity registered in England and Wales, Number 1167484.
We make no warranty whatsoever as to the accuracy or completeness of the FreeBMD data. Use of the FreeBMD website is conditional upon acceptance of the Terms and Conditions |
 |